Machine learning (ML) has evolved rapidly in recent years, with various tools and frameworks available to support the entire workflow. However, managing the ML lifecycle can be complex and challenging. This is where MLflow comes in. MLflow is an open-source platform that manages the entire ML lifecycle, including experimentation, reproducibility, deployment, and a central model registry. It offers four main components: MLflow Tracking, MLflow Projects, MLflow Models, and MLflow Registry. This article will delve into the key concepts of MLflow and demonstrate its use through practical examples.
The Machine Learning Workflow and Challenges
Building an ML model requires experimenting with many datasets, data preparation steps, and algorithms. Once the model is built, it has to be deployed into a production system, its performance monitored, and retraining on new data needs to be continuously performed. This process can be challenging because:
- Difficulty in tracking experiments: Keeping track of which data, code, and parameters were used to obtain a specific result can be problematic when just working with files or interactive notebooks.
- Reproducibility issues: Ensuring that the code gives the same result repeatedly requires tracking code versions, parameters, and the entire environment, including library dependencies. This becomes even more challenging when the code needs to be shared with other data scientists or run at scale on a different platform.
- Lack of standardization for packaging and deploying models: Different data science teams often have their ways of packaging and deploying models, which can lead to a loss of link between a model and the code and parameters that created it.
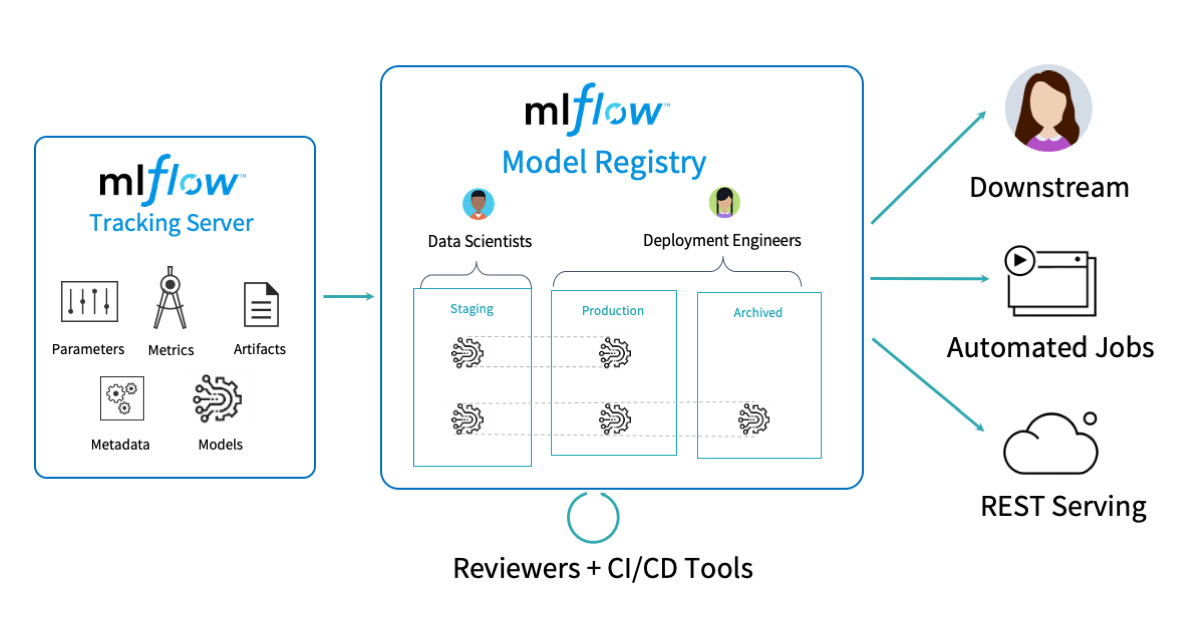
- Absence of a central model management store: Without a central place to collaborate and manage the lifecycle of models, data science teams can struggle with model stage management, from development to staging and finally to archiving or production.
Components of MLflow
MLflow was designed to address these challenges by providing a platform that works with any ML library, is easy to integrate into existing codebases, and makes code reproducible and reusable. Here’s how MLflow’s four components support ML workflows:
- MLflow Tracking: This API and UI log parameters, code versions, metrics, and artifacts during ML code execution. It allows results to be visualized later on local files or a server. Example usage:
- MLflow Projects: These package reusable data science code in a standard format. Each project is a directory with code or a Git repository and includes a descriptor file specifying its dependencies and how to run the code. Here is an example of an MLproject file:
- MLflow Models: MLflow models offer a convention for packaging ML models in multiple flavors, making them easier to deploy. Example usage:
- MLflow Model Registry: This is a centralized model store with a set of APIs and a UI designed to manage the full lifecycle of an MLflow model, including versioning and stage transitions.
Referencing Artifacts in MLflow
In MLflow APIs, how you specify an artifact’s location depends on the API in use. For the Tracking API, artifact locations are specified using a tuple of (run ID, relative path). For the Models and Projects APIs, you specify the location directly. For example:
pythonCopy code
mlflow.log_artifact(“/path/to/local/model”, “artifact_path”)
Scalability with MLflow
MLflow supports scalability across multiple dimensions, allowing individual MLflow runs to execute on a distributed cluster, launching multiple runs in parallel with different parameters, and interfacing with distributed storage systems for input and output.
Practical Use Cases of MLflow
- Individual Data Scientists: MLflow Tracking can track experiments locally, organize code in projects for future reuse, and output models for production deployment using MLflow’s deployment tools.
- Data Science Teams: A team can deploy an MLflow Tracking server to log and compare results across multiple users. Additionally, any team member can download and run another user’s model.
- Large Organizations: MLflow allows teams to share projects, models, and results. Engineering teams can easily transition workflows from R&D to staging to production.
- Production Engineers: They can deploy models from diverse ML libraries in the same way, store models in a management system of choice, and track the source run of a model.
- Researchers and Open Source Developers: MLflow Projects make it easy for anyone to run their code using the command mlflow run github.com/…
Ensuring Reproducibility with MLflow
Reproducibility is a major challenge in machine learning. In addition to the code and parameters, MLflow enables you to capture the entire environment of your run, which is crucial for reproducibility. When you use MLflow projects, you can specify the dependencies of your code in a Conda environment, which MLflow automatically uses to run your code. This ensures that your code runs in the same environment, regardless of the platform it is being run on, thereby ensuring consistent results.
For example, consider a Conda environment specification in a condo.yaml
CODRE
When you run a project with the above Conda, yaml file, MLflow creates a new Conda environment with the specified dependencies, ensuring that your code runs in the same environment every time.
Integrating MLflow with Other Tools
MLflow is designed to work well with other data science and machine learning tools. You can easily integrate MLflow into your existing machine learning workflow, regardless of the libraries and tools you are using.
For example, if you’re using Jupyter Notebooks for interactive data analysis and prototyping, you can use MLflow to track experiments directly from your notebook. Here is how you can log parameters, metrics, and artifacts (such as plots) from a Jupyter Notebook:
MLflow’s modular design allows you to use it with many popular machine-learning libraries, such as scikit-learn, PyTorch, and TensorFlow. Furthermore, it supports logging and serving models in several different formats, allowing you to use your preferred tools for training and serving models.
Model Deployment with MLflow
After training a model, you often need to deploy it for inference. MLflow Models simplify the process of deploying models in diverse serving environments. For example, a model can be deployed as a REST API using the MLflow’s built-in serving tool:
The above command will start a local REST server on port 1234 and serve the model as a REST API, which you can then interact with using HTTP requests.
In addition, MLflow provides tools to deploy models to cloud platforms such as Microsoft Azure ML and Amazon SageMaker, as well as Apache Spark for batch and streaming inference.
Closing Thoughts
MLflow’s goal is to simplify the machine learning lifecycle and provide a unified platform to manage all process stages, from data preparation to model deployment. It’s open-source and integrates well with other tools, making it a versatile choice for teams and organizations of all sizes. By utilizing MLflow’s components effectively, data scientists and engineers can streamline their workflows, collaborate efficiently, and ensure that.
Leave a Reply